Table of Contents
Deployment Overview
One important feature of Gobblin is that it can be run on different platforms. Currently, Gobblin can run in standalone mode (which runs on a single machine), and on Hadoop MapReduce mode (which runs on a Hadoop cluster). This page summarizes the different deployment modes of Gobblin. It is important to understand the architecture of Gobblin in a specific deployment mode, so this page also describes the architecture of each deployment mode.
Gobblin supports Java 7 and up, but can only run on Hadoop 2.x. By default, Gobblin will build against Hadoop 2.x, run ./gradlew clean build. More information on how to build Gobblin can be found here. All directories/paths referred below are relative to gobblin-dist.
Standalone Architecture
The following diagram illustrates the Gobblin standalone architecture. In the standalone mode, a Gobblin instance runs in a single JVM and tasks run in a thread pool, the size of which is configurable. The standalone mode is good for light-weight data sources such as small databases. The standalone mode is also the default mode for trying and testing Gobblin.
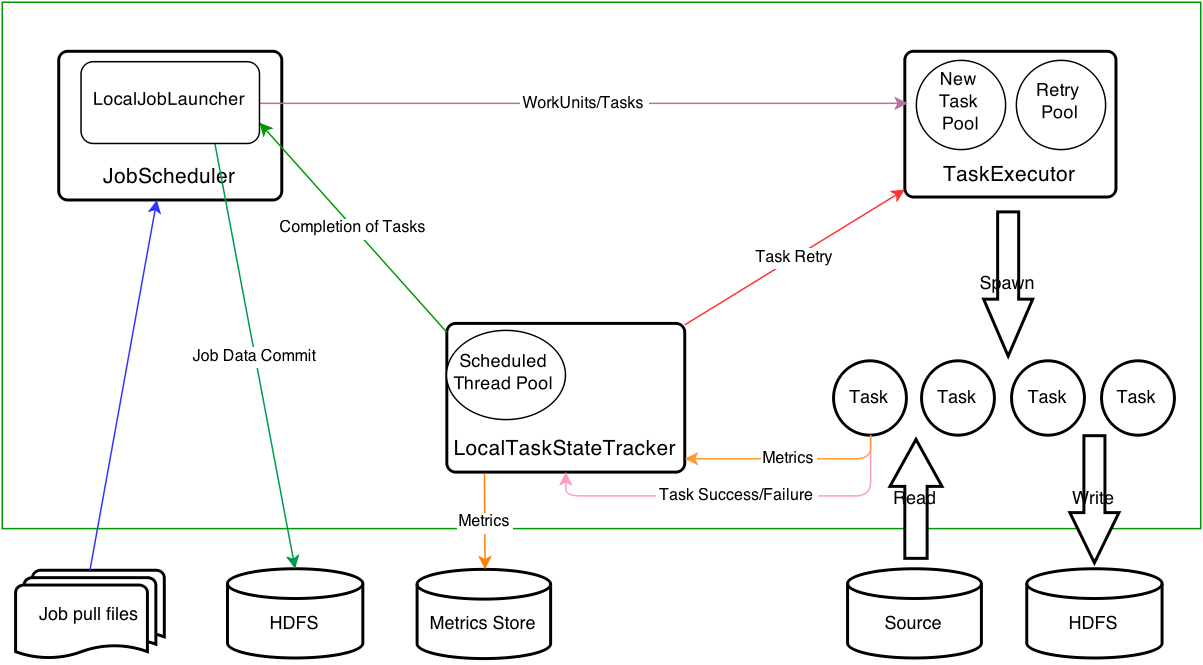
In the standalone deployment, the JobScheduler runs as a daemon process that schedules and runs jobs using the so-called JobLaunchers. The JobScheduler maintains a thread pool in which a new JobLauncher is started for each job run. Gobblin ships with two types of JobLaunchers, namely, the LocalJobLauncher and MRJobLauncher for launching and running Gobblin jobs on a single machine and on Hadoop MapReduce, respectively. Which JobLauncher to use can be configured on a per-job basis, which means the JobScheduler can schedule and run jobs in different deployment modes. This section will focus on the LocalJobLauncher for launching and running Gobblin jobs on a single machine. The MRJobLauncher will be covered in a later section on the architecture of Gobblin on Hadoop MapReduce.
Each LocalJobLauncher starts and manages a few components for executing tasks of a Gobblin job. Specifically, a TaskExecutor is responsible for executing tasks in a thread pool, whose size is configurable on a per-job basis. A LocalTaskStateTracker is responsible for keep tracking of the state of running tasks, and particularly updating the task metrics. The LocalJobLauncher follows the steps below to launch and run a Gobblin job:
- Starting the
TaskExecutorandLocalTaskStateTracker. - Creating an instance of the
Sourceclass specified in the job configuration and getting the list ofWorkUnits to do. - Creating a task for each
WorkUnitin the list, registering the task with theLocalTaskStateTracker, and submitting the task to theTaskExecutorto run. - Waiting for all the submitted tasks to finish.
- Upon completion of all the submitted tasks, collecting tasks states and persisting them to the state store, and publishing the extracted data.
Standalone Deployment
Gobblin ships with a script bin/gobblin-standalone.sh for starting and stopping the standalone Gobblin daemon on a single node. Below is the usage of this launch script:
gobblin-standalone.sh <start | status | restart | stop> [OPTION]
Where:
--workdir <job work dir> Gobblin's base work directory: if not set, taken from ${GOBBLIN_WORK_DIR}
--jars <comma-separated list of job jars> Job jar(s): if not set, lib is examined
--conf <directory of job configuration files> Directory of job configuration files: if not set, taken from
--help Display this help and exit
In the standalone mode, the JobScheduler, upon startup, will pick up job configuration files from a user-defined directory and schedule the jobs to run. The job configuration file directory can be specified using the --conf command-line option of bin/gobblin-standalone.sh or through an environment variable named GOBBLIN_JOB_CONFIG_DIR. The --conf option takes precedence and will take the value of GOBBLIN_JOB_CONFIG_DIR if not set. Note that this job configuration directory is different from conf, which stores Gobblin system configuration files, in which deployment-specific configuration properties applicable to all jobs are stored. In comparison, job configuration files store job-specific configuration properties such as the Source and Converter classes used.
The JobScheduler is backed by a Quartz scheduler and it supports cron-based triggers using the configuration property job.schedule for defining the cron schedule. Please refer to this tutorial for more information on how to use and configure a cron-based trigger.
Gobblin needs a working directory at runtime, which can be specified using the command-line option --workdir of bin/gobblin-standalone.sh or an environment variable named GOBBLIN_WORK_DIR. The --workdir option takes precedence and will take the value of GOBBLIN_WORK_DIR if not set. Once started, Gobblin will create some subdirectories under the root working directory, as follows:
GOBBLIN_WORK_DIR\
task-staging\ # Staging area where data pulled by individual tasks lands
task-output\ # Output area where data pulled by individual tasks lands
job-output\ # Final output area of data pulled by jobs
state-store\ # Persisted job/task state store
metrics\ # Metrics store (in the form of metric log files), one subdirectory per job.
Before starting the Gobblin standalone daemon, make sure the environment variable JAVA_HOME is properly set to point to the home directory of the Java Runtime Environment (JRE) of choice. When starting the JVM process of the Gobblin standalone daemon, a default set of jars will be included on the classpath. Additional jars needed by your Gobblin jobs can be specified as a comma-separated list using the command-line option --jars of bin/gobblin-standaline.sh. If the --jar option is not set, only the jars under lib will be included.
Below is a summary of the environment variables that may be set for standalone deployment.
GOBBLIN_JOB_CONFIG_DIR: this variable defines the directory where job configuration files are stored.GOBBLIN_WORK_DIR: this variable defines the working directory for Gobblin to operate.JAVA_HOME: this variable defines the path to the home directory of the Java Runtime Environment (JRE) used to run the daemon process.
To start the Gobblin standalone daemon, run the following command:
bin/gobblin-standalone.sh start [OPTION]
After the Gobblin standalone daemon is started, the logs can be found under logs. Gobblin uses SLF4J and the slf4j-log4j12 binding for logging. The log4j configuration can be found at conf/log4j-standalone.xml.
By default, the Gobblin standalone daemon uses the following JVM settings. Change the settings in bin/gobblin-standalone.sh if necessary for your deployment.
-Xmx2g -Xms1g
-XX:+UseConcMarkSweepGC -XX:+UseParNewGC
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution
-XX:+UseCompressedOops
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=<gobblin log dir>
To restart the Gobblin standalone daemon, run the following command:
bin/gobblin-standalone.sh restart [OPTION]
To stop the running Gobblin standalone daemon, run the following command:
bin/gobblin-standalone.sh stop
If there are any additional jars that any jobs depend on, the jars can be added to the classpath using the --jars option.
The script also supports checking the status of the running daemon process using the bin/gobblin-standalone.sh status command.
Hadoop MapReduce Architecture
The digram below shows the architecture of Gobblin on Hadoop MapReduce. As the diagram shows, a Gobblin job runs as a mapper-only MapReduce job that runs tasks of the Gobblin job in the mappers. The basic idea here is to use the mappers purely as containers to run Gobblin tasks. This design also makes it easier to integrate with Yarn. Unlike in the standalone mode, task retries are not handled by Gobblin itself in the Hadoop MapReduce mode. Instead, Gobblin relies on the task retry mechanism of Hadoop MapReduce.
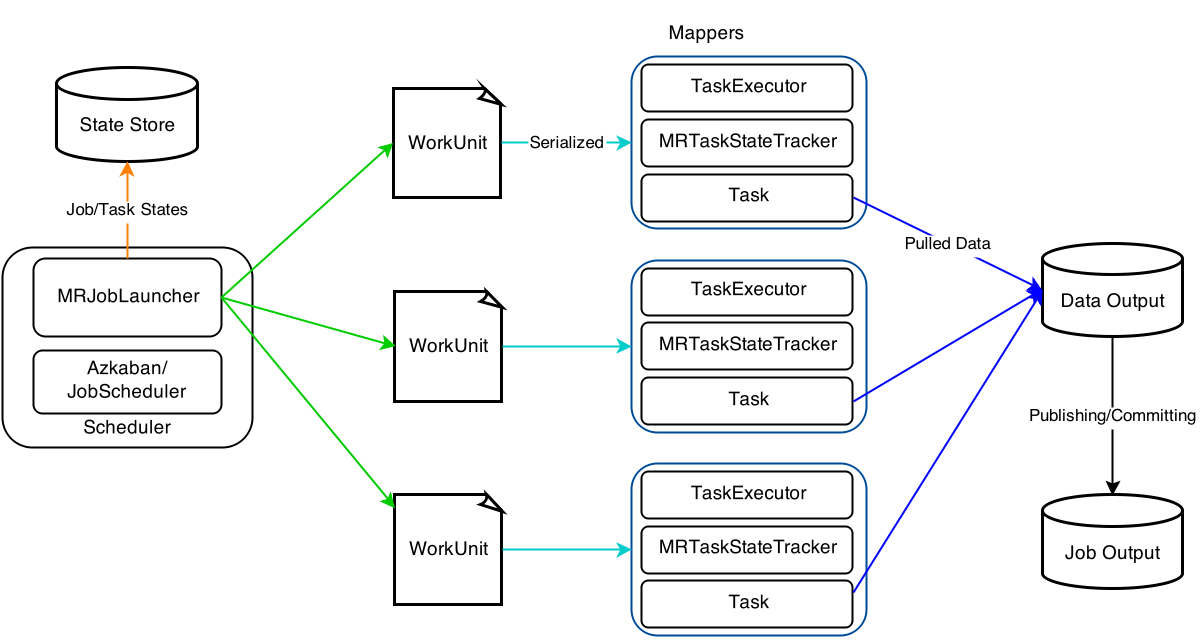
In this mode, a MRJobLauncher is used to launch and run a Gobblin job on Hadoop MapReduce, following the steps below:
- Creating an instance of the
Sourceclass specified in the job configuration and getting the list ofWorkUnits to do. - Serializing each
WorkUnitinto a file on HDFS that will be read later by a mapper. - Creating a file that lists the paths of the files storing serialized
WorkUnits. - Creating and configuring a mapper-only Hadoop MapReduce job that takes the file created in step 3 as input.
- Starting the MapReduce job to run on the cluster of choice and waiting for it to finish.
- Upon completion of the MapReduce job, collecting tasks states and persisting them to the state store, and publishing the extracted data.
A mapper in a Gobblin MapReduce job runs one or more tasks, depending on the number of WorkUnits to do and the (optional) maximum number of mappers specified in the job configuration. If there is no maximum number of mappers specified in the job configuration, each WorkUnit corresponds to one task that is executed by one mapper and each mapper only runs one task. Otherwise, if a maximum number of mappers is specified and there are more WorkUnits than the maximum number of mappers allowed, each mapper may handle more than one WorkUnit. There is also a special type of WorkUnits named MultiWorkUnit that group multiple WorkUnits to be executed together in one batch in a single mapper.
A mapper in a Gobblin MapReduce job follows the step below to run tasks assigned to it:
- Starting the
TaskExecutorthat is responsible for executing tasks in a configurable-size thread pool and theMRTaskStateTrackerthat is responsible for keep tracking of the state of running tasks in the mapper. - Reading the next input record that is the path to the file storing a serialized
WorkUnit. - Deserializing the
WorkUnitand adding it to the list ofWorkUnits to do. If the input is aMultiWorkUnit, theWorkUnits it wraps are all added to the list. Steps 2 and 3 are repeated until all assignedWorkUnits are deserialized and added to the list. - For each
WorkUniton the list ofWorkUnits to do, creating a task for theWorkUnit, registering the task with theMRTaskStateTracker, and submitting the task to theTaskExecutorto run. Note that the tasks may run in parallel if theTaskExecutoris configured to have more than one thread in its thread pool. - Waiting for all the submitted tasks to finish.
- Upon completion of all the submitted tasks, writing out the state of each task into a file that will be read by the
MRJobLauncherwhen collecting task states. - Going back to step 2 and reading the next input record if available.
Hadoop MapReduce Deployment
Gobblin out-of-the-box ships with a script bin/gobblin-mapreduce.sh for launching a Gobblin job on Hadoop MapReduce. Below is the usage of this launch script:
Usage: gobblin-mapreduce.sh [OPTION] --conf <job configuration file>
Where OPTION can be:
--jt <job tracker / resource manager URL> Job submission URL: if not set, taken from ${HADOOP_HOME}/conf
--fs <file system URL> Target file system: if not set, taken from ${HADOOP_HOME}/conf
--jars <comma-separated list of job jars> Job jar(s): if not set, lib is examined
--workdir <job work dir> Gobblin's base work directory: if not set, taken from ${GOBBLIN_WORK_DIR}
--projectversion <version> Gobblin version to be used. If set, overrides the distribution build version
--logdir <log dir> Gobblin's log directory: if not set, taken from ${GOBBLIN_LOG_DIR} if present. Otherwise ./logs is used
--help Display this help and exit
It is assumed that you already have Hadoop (both MapReduce and HDFS) setup and running somewhere. Before launching any Gobblin jobs on Hadoop MapReduce, check the Gobblin system configuration file located at conf/gobblin-mapreduce.properties for property fs.uri, which defines the file system URI used. The default value is hdfs://localhost:8020, which points to the local HDFS on the default port 8020. Change it to the right value depending on your Hadoop/HDFS setup. For example, if you have HDFS setup somwhere on port 9000, then set the property as follows:
fs.uri=hdfs://<namenode host name>:9000/
Note that if the option --fs of bin/gobblin-mapreduce.sh is set, the value of --fs should be consistent with the value of fs.uri.
All job data and persisted job/task states will be written to the specified file system. Before launching any jobs, make sure the environment variable HADOOP_BIN_DIR is set to point to the bin directory under the Hadoop installation directory. Similarly to the standalone deployment, the Hadoop MapReduce deployment also needs a working directory, which can be specified using the command-line option --workdir of bin/gobblin-mapreduce.sh or the environment variable GOBBLIN_WORK_DIR. Note that the Gobblin working directory will be created on the file system specified above. Below is a summary of the environment variables that may be set for deployment on Hadoop MapReduce:
GOBBLIN_WORK_DIR: this variable defines the working directory for Gobblin to operate.HADOOP_BIN_DIR: this variable defines the path to thebindirectory under the Hadoop installation directory.
This setup will have the minimum set of jars Gobblin needs to run the job added to the Hadoop DistributedCache for use in the mappers. If a job has additional jars needed for task executions (in the mappers), those jars can also be included by using the --jars option of bin/gobblin-mapreduce.sh or the following job configuration property in the job configuration file:
job.jars=<comma-separated list of jars the job depends on>
The --projectversion controls which version of the Gobblin jars to look for. Typically, this value is dynamically set during the build process. Users should use the bin/gobblin-mapreduce.sh script that is copied into the gobblin-distribution-[project-version].tar.gz file. This version of the script has the project version already set, in which case users do not need to specify the --projectversion parameter. If users want to use the gobblin/bin/gobblin-mapreduce.sh script they have to specify this parameter.
The --logdir parameter controls the directory where log files are written to. If not set log files are written under a the ./logs directory.